Мониторинг с алертами в Telegram: гибкие правила и синтетические проверки в admin-панели

Панель уже умеет показывать логи, аналитику и ошибки в реальном времени. Но это всё равно «открыл и проверил». Открыл утром — узнал что было ночью. Открыл вечером — узнал что было днём. Пока ты не смотришь, панель молчит, даже если API падает.
Я хотел другого: чтобы система сама сообщала, когда что-то идёт не так. Не «посмотри логи» — а «пришло сообщение в Telegram, вот что случилось». Так появился раздел «Monitoring».
Он делится на три независимых блока. Первый — профили Telegram-ботов: куда и через кого отправлять уведомления. Второй — правила алертов: гибкие условия срабатывания по входящему трафику. Третий — синтетические проверки: активный пинг внешних и внутренних эндпоинтов по расписанию.
Telegram Боты
Первое решение, которое нужно было принять — как устроена конфигурация отправки. Очевидный вариант: одно поле «токен», одно поле «chat_id», глобально на всё приложение. Я так и начинал.
Но когда начал думать, как это будет выглядеть в реальной эксплуатации — стало понятно, что один бот не подходит. Сервис обслуживает несколько проектов. Алерты по платёжному API не должны лететь туда же, куда летят общие технические уведомления. Ночные крит-алерты должны идти в отдельный канал с уведомлениями на телефоне, а дневные — в рабочий чат. Стейджинговый стенд — в свой чат, продакшн — в свой.
Поэтому вместо одной глобальной строки — таблица ботов. Каждый бот — отдельная сущность в базе: имя, токен, chat_id, статус включён/выключен. Имя — произвольная строка, только для навигации внутри панели: «Ops», «Payments», «Staging», что угодно.
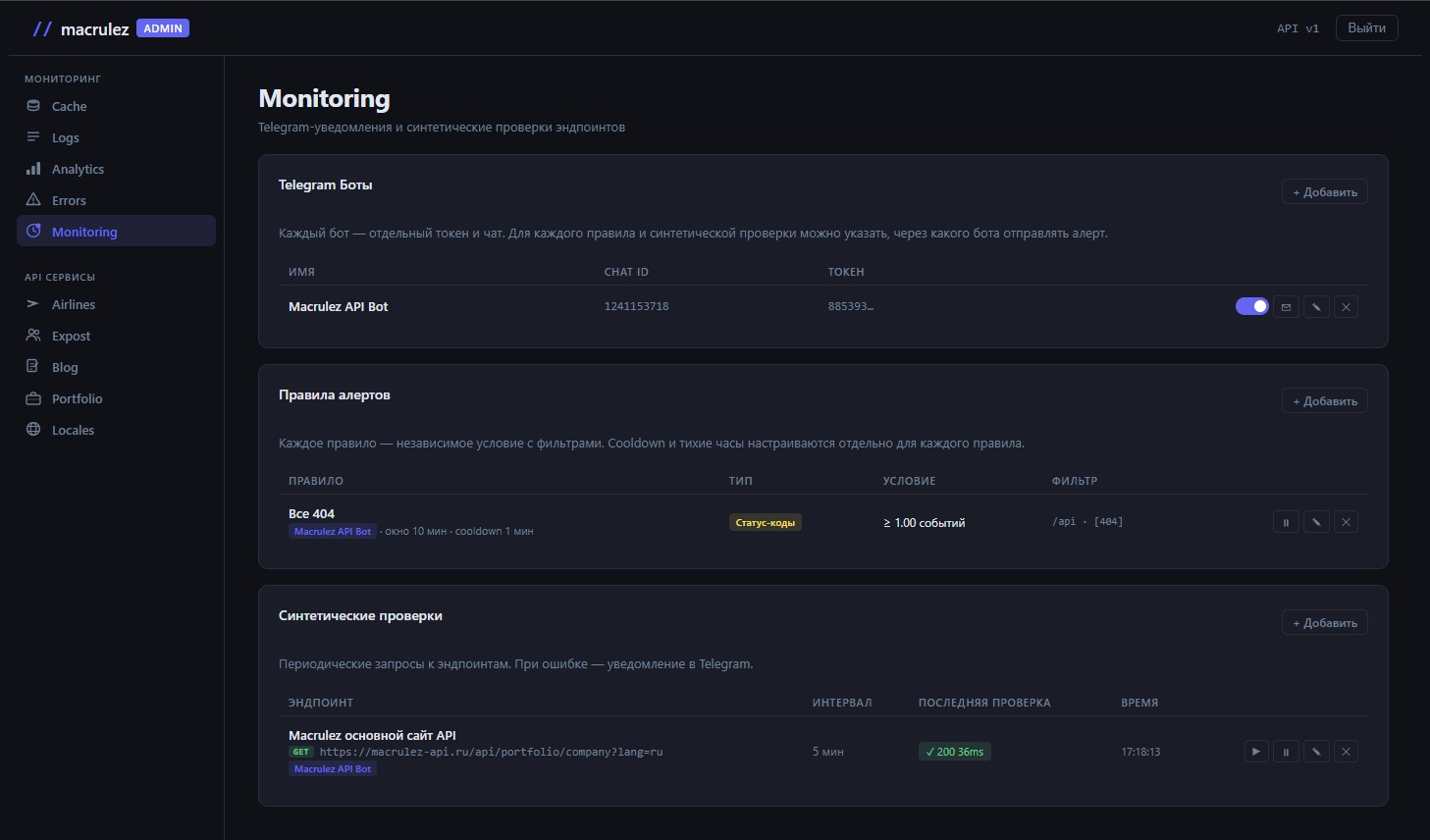
Как выглядит таблица
Строка на каждого бота: имя, числовой ID чата, замаскированный токен — первые шесть символов плюс многоточие. Полный токен нигде не отображается после сохранения. Достаточно, чтобы понять, какой бот привязан к какому проекту, и не светить чувствительные данные в интерфейсе.
Справа — три действия. Тоггл вкл/выкл: выключенный бот не получает никаких уведомлений, но вся его конфигурация и все привязанные к нему правила сохраняются. Кнопка ✉ — тест: отправляет в указанный чат простое сообщение «✅ Тестовое сообщение. Мониторинг работает.». Кнопки редактировать и удалить.
Тест — принципиально важная вещь. Без неё единственный способ убедиться, что бот работает — дождаться реального алерта. Бот может не работать по десятку причин: неверный токен, бот не добавлен в канал, нет прав на отправку сообщений. Нажал тест — через секунду знаешь, всё ли в порядке.
Форма добавления и редактирования
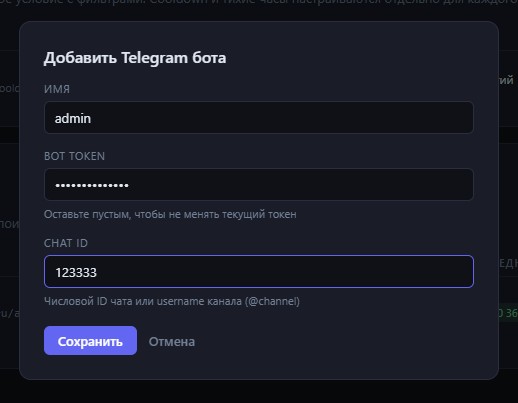
Три поля: имя, токен, chat_id. Всё обязательно при создании. При редактировании токен можно оставить пустым — тогда он не обновится, останется текущий. Полезно, если нужно просто поменять название или чат, а токен под рукой нет.
Кнопка сохранения заблокирована, пока не заполнены обязательные поля. При создании — все три. При редактировании — имя и chat_id, токен опционален.
Привязка к правилам и проверкам
Ключевая деталь: бот выбирается не глобально, а для каждого правила алертов и каждой синтетической проверки отдельно. Одно правило → один конкретный бот. Это даёт полный контроль над маршрутизацией уведомлений: алерты по разным частям системы идут в разные каналы, без общего потока.
Если у правила нет привязанного бота — оно не будет отправлять уведомления, даже если условие сработает. Это тоже полезно: иногда хочется добавить правило «вхолостую», посмотреть как оно срабатывает, и только потом включить реальную отправку.
Правила алертов
Здесь была самая интересная часть проектирования. Стандартный подход — одна глобальная настройка: «алертить если error rate > X%». Это работает, пока у тебя один монолитный API и однородный трафик. Как только появляется разнородность — всё ломается.
Пример: у эндпоинта /api/search нормальный error rate 8% — пользователи ищут несуществующие авиалинии, получают 404, это штатная ситуация. А для /api/payments даже 1% — это уже проблема. Один глобальный порог или слишком чувствительный для search, или слишком мягкий для payments.
Решение — правила. Не одна настройка, а неограниченный набор независимых условий. Каждое — со своими фильтрами, своим порогом, своим cooldown, своим ботом. Правила не конфликтуют: одно срабатывание не блокирует другое.
Тип условия: Error Rate
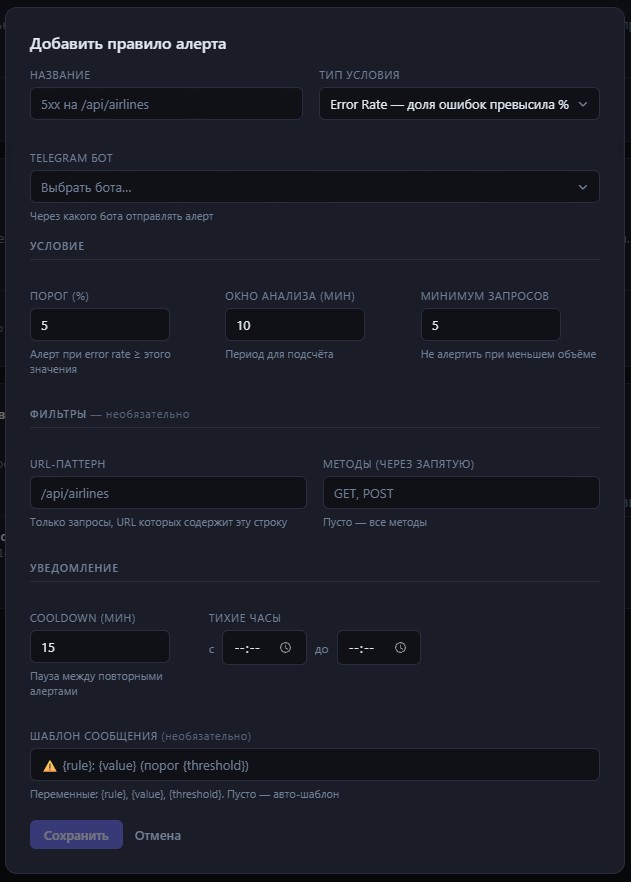
Считает долю ошибочных ответов (статусы 400 и выше) от всех запросов за указанное окно. Порог — в процентах.
Настраивается три числа. Порог — сколько процентов ошибок нужно, чтобы алерт сработал. Окно анализа — за какой период смотреть в минутах: 5, 10, 30, что угодно. Чем шире окно — тем сглаженнее значение, меньше ложных срабатываний от кратких всплесков. Минимум запросов — нижняя граница по объёму: если за всё окно пришло меньше этого числа запросов, правило не срабатывает. Без этого параметра ночью при пяти запросах и двух ошибках error rate мгновенно улетает в 40% и будит среди ночи.
Практический пример: правило «общее здоровье API» — error rate выше 3%, окно 10 минут, минимум 50 запросов. Ещё одно правило — «критичный эндпоинт бронирования» — error rate выше 0.5%, окно 5 минут, минимум 10 запросов, URL-паттерн /api/booking. Оба работают независимо, второе в десять раз чувствительнее.
Тип условия: Status Codes
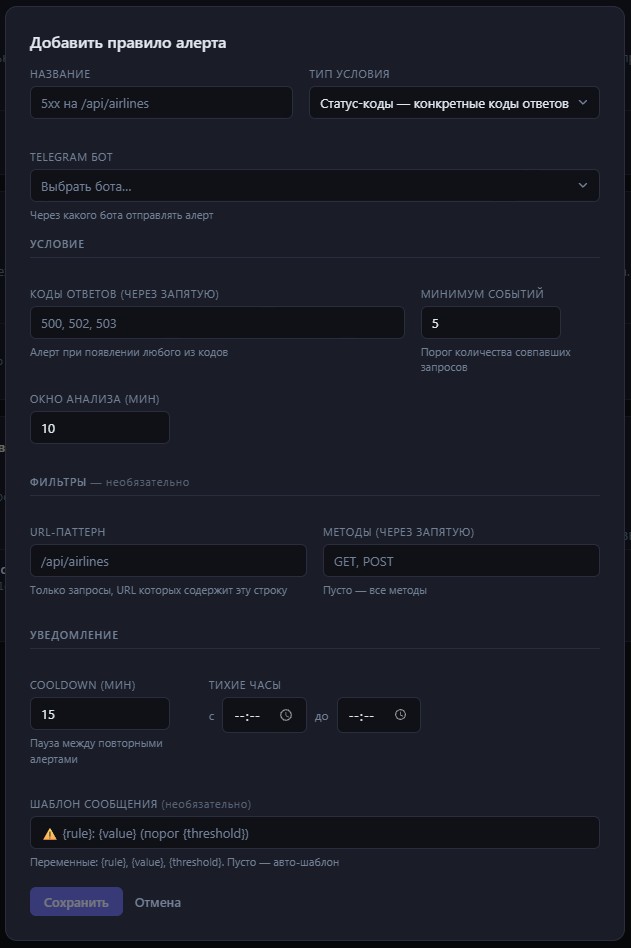
Реагирует на конкретные HTTP-коды, а не на долю ошибок. Указываешь список кодов через запятую: например, 500, 502, 503. Порог — минимальное количество таких запросов за окно.
Разница с error rate принципиальная. Error rate — процент, он размывает картину при высоком трафике. Если за 10 минут пришло 10 000 запросов и 20 из них вернули 503 — error rate 0.2%, ниже любого разумного порога. Но двадцать 503 за десять минут — это уже симптом чего-то нехорошего. Status Codes поймает это там, где error rate промолчит.
Другой кейс: игнорировать 404 вообще, но реагировать на каждый 503 немедленно. Создаёшь правило «любой 503», порог 1, окно 5 минут. Один 503 — уже уведомление.
Или наоборот: 404 нормально появляются от поисковых ботов, но если их вдруг стало 500 за минуту — значит что-то сломалось. Правило «массовые 404» — код 404, порог 500, окно 1 минута.
Тип условия: Slow Response
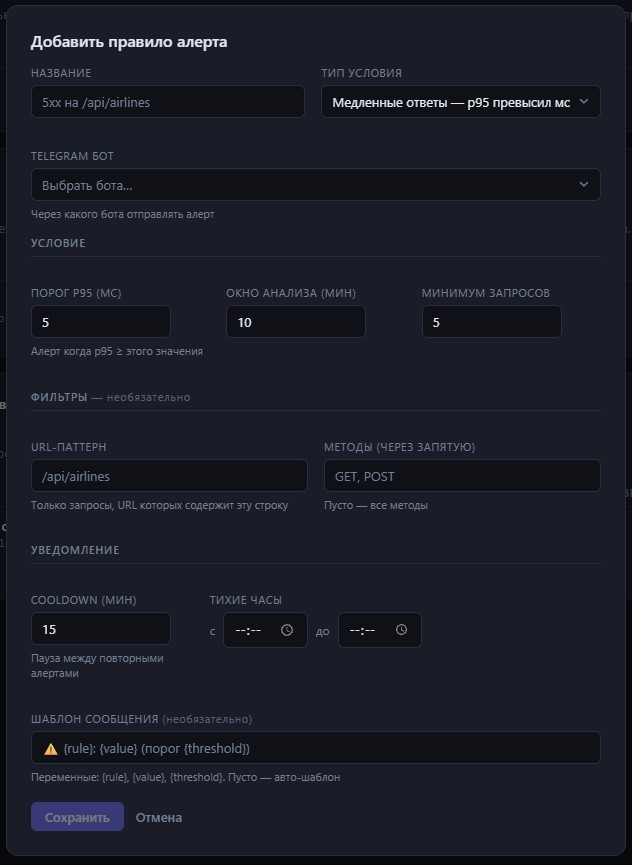
Смотрит на p95 latency за окно. p95 — это значение, ниже которого укладываются 95% запросов. Порог задаётся в миллисекундах.
Почему p95, а не среднее — уже объяснял в посте про аналитику. Среднее в 120 мс при p95 в 3500 мс — это нормальное среднее и катастрофическое хвостовое значение одновременно. Среднее скрывает проблему; p95 обнажает её.
Используется для двух вещей. Первое — общее замедление: если в целом API стало тормозить, p95 вырастет по всем эндпоинтам. Второе — деградация конкретного компонента: правило с URL-паттерном на /api/airlines/graphql поймает замедление только этого эндпоинта, не реагируя на остальные.
Настройки те же: порог, окно, минимум запросов (чтобы ночью при трёх медленных запросах p95 не создавал алерт).
Фильтры
Фильтры — механизм, который даёт правилам точность. Без них каждое правило работает по всему трафику целиком. С фильтрами — только по нужному срезу.
URL-паттерн — произвольная подстрока. Правило с паттерном /api/payments анализирует только запросы, в URL которых встречается эта строка. Регистронезависимо. Паттерн не поддерживает regexp намеренно: подстроки достаточно для большинства задач, а regexp добавляет сложность конфигурации без реальной пользы для этого уровня фильтрации.
Несколько правил на один и тот же эндпоинт — нормальная ситуация. Правило «error rate на /api/search, порог 10%» и правило «5xx на /api/search, порог 1 событие» работают параллельно. Первое поймает общее ухудшение, второе — первый же серверный сбой.
Методы — список HTTP-методов. Перечисляешь через запятую: POST, PUT, PATCH. Пусто — все методы.
Смысл в том, что разные методы имеют разную семантику ошибок. GET-запросы ошибаются от того, что данных нет — это часто нормально. POST и PUT ошибаются от того, что что-то не записалось — это никогда не нормально. Правило «любая 500 на мутациях» без паттерна, методы POST, PUT, DELETE — и ты всегда знаешь, когда запись в базу стала давать сбои.
Фильтры комбинируются: паттерн URL и методы работают вместе. Правило «5xx на POST /api/orders» — это паттерн /api/orders и метод POST.
Настройки уведомления
Cooldown — пауза между повторными алертами по одному правилу, в минутах. Это самый важный параметр после порога.
Без cooldown: условие сработало, пришёл алерт. Минуту спустя проверка прошла снова, условие снова выполняется — ещё алерт. И так каждую минуту, пока инцидент не закрыт. За час инцидента — 60 одинаковых сообщений. Бот превращается в источник шума, на который перестают реагировать.
С cooldown: первый алерт пришёл. Следующий — не раньше чем через cooldown минут, даже если условие всё ещё выполняется. Поставить 30 минут — разумный баланс: знаешь, что проблема есть, но чат не завален. Для критичных правил — 5–10 минут, для фоновых — 60.
Важно: cooldown независимый на каждое правило. Одно правило в режиме тишины не блокирует другие.
Тихие часы — временной диапазон, в который алерты не отправляются вообще. Поля «с» и «до» в формате HH:MM.
Типичный сценарий: плановое обслуживание баз данных с 03:00 до 05:00. В это время error rate растёт, но это ожидаемо. Без тихих часов — разбудят. С тихими часами — нет. Переход через полночь поддерживается: «с 23:30 до 06:00» корректно работает как период с ночи до утра.
Тихие часы не блокируют cooldown: если алерт не ушёл в тихие часы, cooldown для этого правила не обнуляется. Проверка на тихое время происходит до проверки cooldown.
Шаблон сообщения — необязательное поле. Если оставить пустым, сообщение генерируется автоматически: иконка по типу (⚠️ для error rate, 🔴 для статус-кодов, 🐢 для медленных ответов), название правила, текущее значение, фильтры, количество запросов за окно. Для большинства случаев автошаблона достаточно.
Если нужен свой формат: пишешь текст с переменными {rule} — имя правила, {value} — значение на момент срабатывания (например, «7.3% (порог: 5%)»), {threshold} — заданный порог. Например: 🔥 Внимание! {rule} превысил допустимый уровень: {value}.
Бот — выпадающий список из всех добавленных ботов. Пусто — правило срабатывает, но ничего не отправляет. Полезно во время настройки: создал правило, смотришь как оно срабатывает по логам сервера, потом подключаешь бота.
Как выглядит в интерфейсе
Таблица правил: название, цветной бейдж типа условия (красный — Error Rate, жёлтый — Status Codes, фиолетовый — Slow Response), условие срабатывания в одну строку (≥ 5%, ≥ 1 событий, p95 ≥ 2000ms), фильтр в одну строку (/api/payments · POST · [500, 503]), имя привязанного бота.
Кнопка ⏸ — поставить на паузу. Правило не удаляется, просто перестаёт проверяться. Удобно на время деплоя или обслуживания, когда не хочется получать алерты о плановых ошибках, но и удалять правило не нужно.
В форме создания/редактирования — секции с разделителями: «Условие», «Фильтры», «Уведомление». Поля под условием меняются в зависимости от выбранного типа: для error_rate — порог, окно, минимум запросов; для status_code — коды и окно; для slow_response — порог p95 и окно.
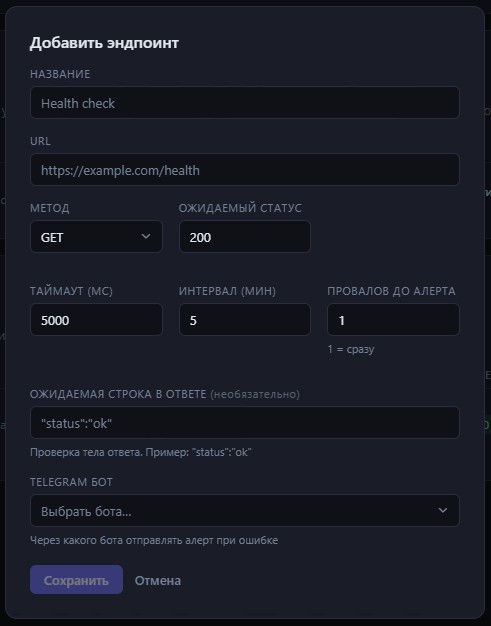
Синтетические проверки
Правила алертов — реактивный инструмент: они смотрят на трафик, который уже пришёл. Но есть класс проблем, которые они не увидят.
Если сторонний сервис лёг, а пользователи сегодня ночью не обращались к зависящему эндпоинту — в буфере запросов тишина. Если healthcheck страницы отдаёт 500, но к ней не ходят через API — алертов не будет. Если база данных перестала принимать соединения в 3 утра — первым об этом узнает не мониторинг, а пользователь в 9 утра.
Синтетические проверки решают это иначе: сам сервис периодически активно стучится к нужным URL и проверяет ответ. Пользователей может не быть — проверка всё равно идёт.
Что можно проверять
URL — любой HTTP или HTTPS адрес. Это может быть эндпоинт самого сервиса (http://localhost:3000/health), внешний API-партнёр (https://api.partner.com/ping), или вообще любой URL, работоспособность которого важна.
Метод — GET, POST или HEAD. HEAD — специальный случай: сервер обрабатывает запрос как GET, но не возвращает тело ответа. Для healthcheck-эндпоинтов, которые просто возвращают 200, HEAD экономит трафик и чуть ускоряет проверку. GET — стандартный вариант для всего остального. POST — если эндпоинт требует именно POST (с пустым телом).
Ожидаемый статус — HTTP-код, который считается успехом. По умолчанию 200. Если эндпоинт при правильной работе возвращает 204 No Content, 201 Created или любой другой код — указываешь именно его. Любое отклонение считается провалом.
Таймаут — максимальное время ожидания ответа, в миллисекундах. По истечении таймаута запрос прерывается и проверка считается провалом с ошибкой «Таймаут (5000ms)». Это важно: сервис может не падать, а просто зависать — отвечать через 30 секунд вместо 200 мс. Без таймаута проверка ждала бы вечно; с ним — фиксирует проблему и двигается дальше.
Интервал — как часто запускать проверку, в минутах. Для критичных внешних зависимостей — раз в 1–2 минуты. Для менее важных — раз в 10–15. Всё работает через один setInterval на бэкенде: каждую минуту сервис смотрит по каждому включённому эндпоинту, прошло ли достаточно времени с последней проверки, и если да — запускает.
Провалов до алерта — сколько неудачных проверок подряд должно произойти, прежде чем уведомление уйдёт в Telegram. Значение 1 — алерт немедленно при первой ошибке. Значение 3 — алерт только если три проверки подряд провалились.
Этот параметр убирает ложные срабатывания от эфемерных проблем. Мимолётная сетевая ошибка, кратковременная перегрузка DNS, одиночный таймаут из-за GC-паузы — всё это дало бы поток ненужных уведомлений при значении 1. С провалами до алерта = 3 такие случаи проходят молча; уведомление приходит только когда проблема устойчивая и повторяется.
После того, как нужное количество провалов накоплено и алерт отправлен — счётчик сбрасывается. Следующий алерт снова потребует N провалов подряд. Но между ними — если хотя бы одна проверка прошла успешно — счётчик обнуляется немедленно.
Ожидаемая строка в теле — необязательное поле для проверки содержимого ответа. Сервер вернул 200 — это не всегда означает, что всё в порядке. Некоторые сервисы возвращают 200 даже в состоянии деградации, просто с другим телом. Указываешь строку, которая должна присутствовать в ответе: например "status":"ok", healthy или любой маркер работоспособности. Если строка не найдена — проверка считается провалом, несмотря на правильный статус.
Практический пример: API-партнёр иногда возвращает 200 с телом {"status":"maintenance","message":"Ведутся работы"}. Без проверки тела — всё выглядит нормально. С проверкой строки "status":"ok" — провал, уведомление.
Бот — через какого бота слать уведомление. Так же как для правил алертов — выбирается из списка добавленных ботов.
Что приходит в Telegram при провале
Сообщение содержит: название эндпоинта, URL, статус-код (или прочерк если таймаут), время ответа в миллисекундах, причину ошибки. Если настроены провалы до алерта больше 1 — в сообщении будет указано «(N/M подряд)»: сразу понятно, что это устойчивая проблема, а не флукс.
Таблица и ручной запуск
Каждая проверка в таблице — строка: название, метод с цветовым бейджем и URL, интервал, результат последней проверки, время когда проводилась. Результат — зелёный бейдж с кодом ответа и временем в миллисекундах при успехе, красный с текстом ошибки при провале. Если проверка ещё ни разу не запускалась — серый прочерк.
Кнопка ▶ — запустить прямо сейчас, не ждя следующего интервала. Исправил проблему — нажал, через секунду видишь результат. Удобно для быстрой проверки после деплоя или исправления инцидента.
Тоггл — включить/выключить проверку. Выключенный эндпоинт не проверяется, но сохраняется со всеми настройками.
Как это устроено внутри
Никаких внешних job-планировщиков. Один setInterval на 60 секунд на бэкенде — единственный таймер для всего мониторинга.
При каждом тике: загружаем из базы все включённые эндпоинты и карту ботов. Для каждого эндпоинта смотрим, прошёл ли нужный интервал с момента последней проверки (храним в памяти в Map<id, timestamp>). Если прошёл — запускаем HTTP-запрос через fetch с AbortController для таймаута. Запросы для разных эндпоинтов идут параллельно, не блокируя друг друга.
После проверки результат пишется в таблицу monitor_results. Для каждого эндпоинта хранится история последних результатов — видно как менялось состояние со временем.
Для алертов по правилам: в том же тике пробегаемся по всем включённым правилам. Данные не запрашиваются из базы — используется кольцевой буфер запросов в памяти, тот самый, что отдаётся в разделе «Логи». Фильтруем буфер по URL-паттерну и методам, считаем метрику за нужное окно. Cooldown держится в памяти как Map<string, timestamp> с ключами вида rule:42 и endpoint:17. Никакой базы данных для cooldown — она здесь избыточна.
Тихие часы проверяются на каждый тик: берём текущее время сервера, сравниваем с диапазоном. Переход через полночь обрабатывается явно: если start > end, то диапазон «оборачивается» через 00:00.
Вся конфигурация живёт в PostgreSQL в схеме api_admin: таблицы bots, alert_rules, monitor_endpoints, monitor_results. Конфигурация читается при каждом тике — это позволяет менять настройки без перезапуска сервера. Добавил правило в UI, нажал «Сохранить» — оно начнёт работать уже на следующей минуте.
Пример: как это работает в связке
Реальный сценарий, который я хотел закрыть: деградация внешней зависимости.
Есть API авиаданных — внешний сервис, к которому обращаются несколько эндпоинтов. Настройки мониторинга:
Синтетическая проверка: URL внешнего API, GET, ожидаемый статус 200, таймаут 5 секунд, интервал 2 минуты, провалов до алерта 2, строка в теле "success":true, бот — «Ops».
Правило алертов: тип «Status Codes», коды 502, 503, URL-паттерн /api/airlines, методы пусто (все), порог 3 события, окно 5 минут, cooldown 20 минут, бот — «Ops».
Ещё одно правило: тип «Slow Response», URL-паттерн /api/airlines, порог p95 3000 мс, окно 10 минут, минимум 10 запросов, cooldown 30 минут, бот — «Ops».
Внешний сервис начинает деградировать в 14:30 — отвечает медленно и иногда с ошибками.
14:32 — синтетическая проверка прошла с таймаутом 5 секунд. Первый провал, счётчик = 1.
14:34 — вторая проверка, снова таймаут. Счётчик = 2, порог достигнут. В «Ops» уходит сообщение: «🔴 Ошибка мониторинга (2/2 подряд). URL. Таймаут (5000ms)». Это произошло за 4 минуты с начала инцидента, без каких-либо жалоб от пользователей.
14:36 — пользователи начали получать 503 при запросах к /api/airlines. Правило «Status Codes» нашло 3 совпадения за 5 минут — отдельное сообщение: «🔴 Статус-коды: 5xx авиалинии. 3 запроса с кодами 502, 503».
14:40 — p95 по /api/airlines пополз выше 3000 мс. Правило «Slow Response» сработало: «🐢 Медленные ответы: Airlines latency. p95 = 3840ms (порог: 3000ms)».
Дальше — cooldown. Пока инцидент длится, чат получает не поминутный спам, а одно уведомление на каждый тип события раз в cooldown-период. Ситуация зафиксирована, контекст понятен, без лишнего шума.
Партнёрский сервис восстановился в 15:10. Следующая синтетическая проверка в 15:12 прошла успешно — счётчик провалов сбросился, следующие тики тихие. Инцидент закрыт.
Весь путь: знаю о проблеме через 4 минуты, понимаю что именно через 6, слежу за развитием без спама. Раньше это обнаруживалось по жалобе пользователя и docker logs | grep 503.