Admin-панель мониторинга: дашборд, аналитика, логи и API-эксплорер

У меня есть собственный Node.js-сервис — REST API, который обслуживает несколько проектов: блог, карту авиамаршрутов и ещё пару штук. Внутри — PostgreSQL, двухуровневый кэш (in-memory + дисковый), HTTP-кэш для публичных ответов. Всё это живёт в Docker-контейнере на VPS.
Долго жил с картиной «сервис работает — значит всё ок». Проблемы обнаруживались либо из логов после факта, либо когда кто-то уже успел написать. Понять, что именно происходит прямо сейчас — у какого эндпоинта p95 пополз вверх, сколько ошибок за последние шесть часов по сравнению с предыдущими шестью, не течёт ли heap — можно было только залезть в docker logs или написать одноразовый скрипт.
Это плохой способ жить. Я сделал admin-панель.
В ней шесть разделов: сводный дашборд, кэш, логи, аналитика API, ошибки и интерактивный API-эксплорер.
Дашборд
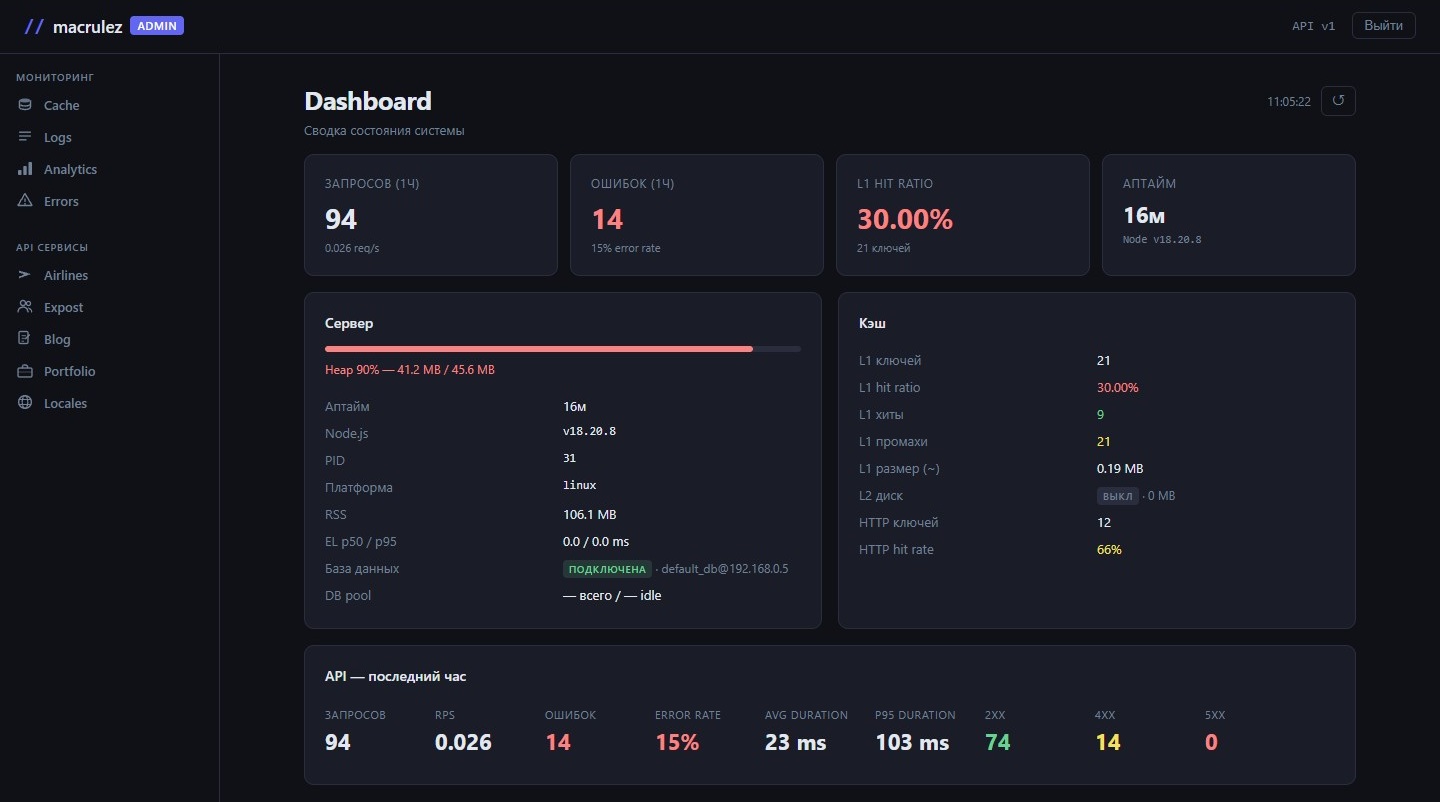
Первое, что видишь при входе в панель — сводный экран. Никаких «выберите метрику и диапазон» — всё основное сразу, без лишних кликов. Дашборд должен отвечать на вопрос «всё ли в порядке» с одного взгляда.
Stat-карточки
Самый верхний ряд — четыре карточки. Запросов за последний час, ошибок за тот же период, L1 hit ratio кэша и аптайм сервера. Под основным числом в каждой карточке — уточняющая строка: под запросами — RPS, под ошибками — процент error rate, под hit ratio — количество ключей в памяти, под аптаймом — версия Node.js.
Цифры раскрашены. Error rate ниже 1% — нейтральный цвет, от 1% до 5% — жёлтый, 5% и выше — красный. Hit ratio кэша оценивается бэкендом по метке эффективности: excellent при hit rate выше 80% — зелёный, good от 60% — жёлтый, ниже — красный. Не нужно каждый раз интерпретировать цифры: достаточно того, есть ли красный на экране или нет.
Справа в шапке — временная метка последнего обновления и кнопка ↺. Нажал — все данные перезагружаются параллельно без перезагрузки страницы.
Панель «Сервер»
Под карточками — две колонки. Левая — состояние сервера.
Сверху — прогресс-бар heap-памяти Node.js-процесса с процентом и абсолютными значениями heapUsed / heapTotal. Полоса меняет цвет: зелёная до 65%, жёлтая до 85%, красная выше.
Ниже — таблица: аптайм в виде 2д 3ч 5м, версия Node.js, PID, платформа, RSS-память. Event loop latency — p50 и p95 в миллисекундах: показывают, не блокируется ли event loop тяжёлыми синхронными операциями. Отдельная строка — статус подключения к базе данных: зелёный бейдж «подключена» и database@host. Следующая строка — пул соединений: всего слотов и сколько сейчас idle.
Панель «Кэш»
Правая колонка — сводка по кэшу. Количество ключей в L1, hit ratio с цветовым индикатором, абсолютные хиты и промахи, приблизительный размер данных в памяти. Ниже — L2 дисковый кэш: включён или нет, размер директории. Если поднят HTTP-кэш ответов API — отдельный блок с количеством закэшированных ответов и hit rate.
API-метрики
Под двумя колонками — блок с метриками API за последний час. Крупные цифры: запросов всего, RPS, ошибок, error rate, среднее время ответа, p95 latency. Рядом — распределение по статусам: 2xx зелёным, 4xx жёлтым, 5xx красным.
p95 принципиально важнее среднего: если среднее 80 мс, а p95 — 1200 мс, значит каждый двадцатый запрос работает совсем иначе. Среднее это скрывало бы.
Кэш
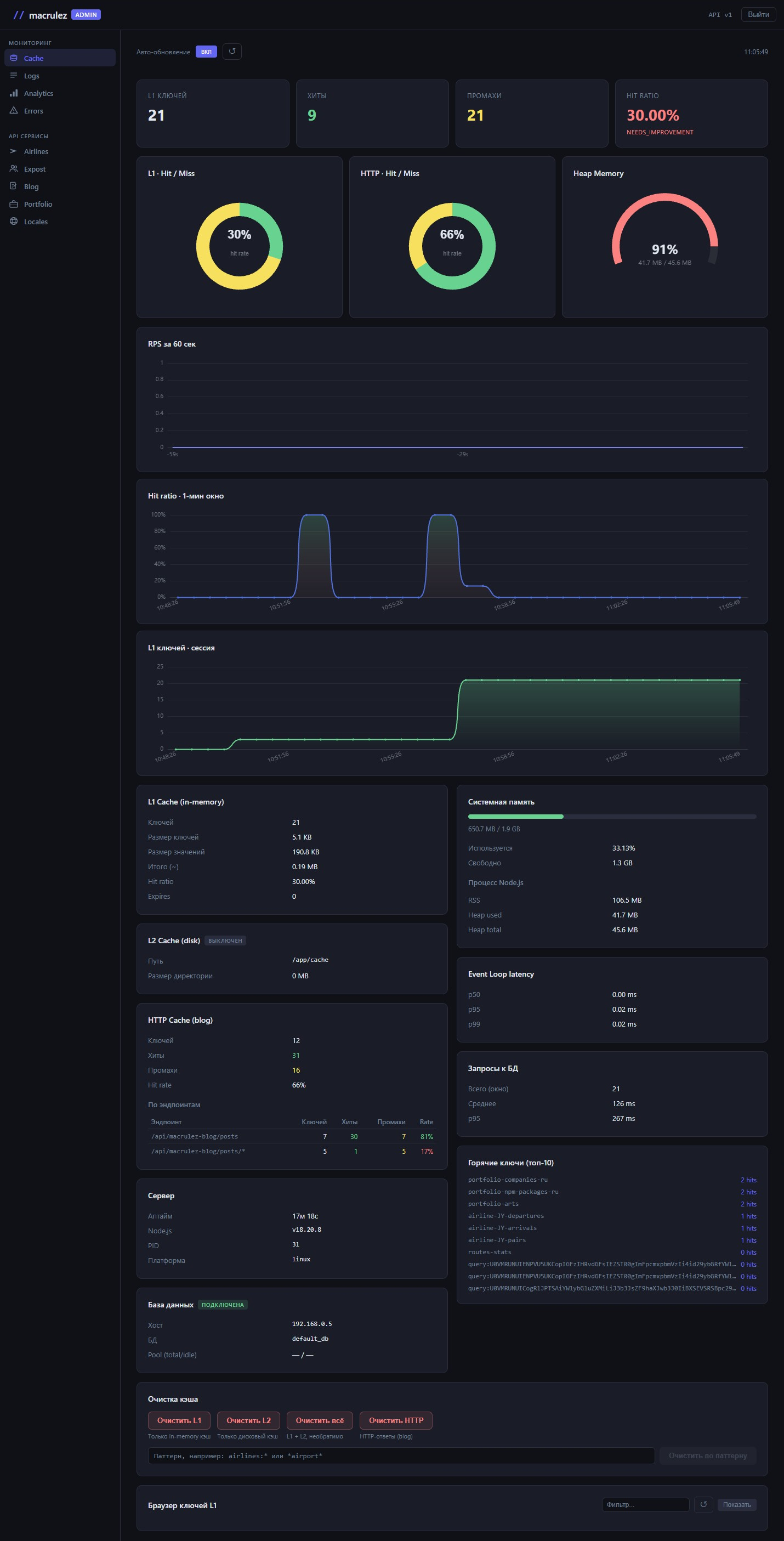
Самый насыщенный раздел. Кэш в сервисе двухуровневый: L1 — in-memory NodeCache для результатов SQL-запросов, L2 — дисковый кэш для долгоживущих данных, плюс HTTP-кэш для ответов публичного API. На экране — состояние каждого из них и инструменты управления.
Stat-карточки и диаграммы
Наверху — четыре карточки: ключей в L1, суммарные хиты, промахи, hit ratio с цветовой меткой эффективности.
Под карточками — первый ряд диаграмм. Два donut-чарта: один для L1-кэша, второй для HTTP-кэша — хиты против промахов, в центре кольца — hit rate числом. Третий элемент — полукруговой gauge heap-памяти. Цвет дуги меняется по заполненности: синий в норме, жёлтый — стоит обратить внимание, красный — пора принимать меры.
Второй ряд — динамика за текущую сессию: RPS за последние 60 секунд, hit ratio в скользящем окне (линия меняет цвет от красного к зелёному в зависимости от значения), количество ключей в L1 — позволяет заметить неожиданный сброс кэша или неконтролируемый рост.
Детальная статистика
Под диаграммами — две колонки.
Левая — L1 в деталях. ksize и vsize раздельно: размер ключей и размер значений по отдельности. Если vsize начинает расти при стабильном ksize — значения стали тяжелее. Количество истёкших записей: резкий рост сигнализирует, что TTL слишком короткий или сервер стал медленнее отвечать.
Правая — HTTP-кэш по эндпоинтам. Для каждого нормализованного префикса URL: количество ключей, хитов, промахов и hit rate с цветом. Благодаря нормализации URL таблица осмысленная: /api/posts (листинг) и /api/posts/* (детальная страница) — отдельные строки с разной статистикой.
Под колонками — состояние сервера: event loop p50/p95/p99, heap с прогресс-баром, пул соединений БД.
Очистка кэша
Четыре кнопки: очистить L1, очистить L2, очистить HTTP-кэш, очистить всё. Раздельные кнопки позволяют точечно управлять: сбросить только устаревшие HTTP-ответы, не трогая прогретый L1, или наоборот.
Первый клик по кнопке показывает inline-подтверждение прямо под кнопкой: «Очистить L1? Да / Отмена». Второй клик выполняет действие. Браузерного window.confirm() нет — всё в рамках интерфейса.
Отдельно — очистка по паттерну. Поддерживает * как wildcard: написал airlines:* — удаляются все ключи с таким префиксом. После выполнения показывается количество удалённых ключей.
Браузер ключей
По умолчанию скрыт — появляется по кнопке «Показать ключи». Загружается лениво: данные запрашиваются только при первом открытии, не при загрузке страницы.
Таблица: имя ключа, оставшийся TTL в виде 4м 20с или 2ч 15м, размер значения в байтах, количество хитов. TTL раскрашен по срочности: меньше 5 минут до истечения — красный, меньше 30 минут — жёлтый. Над таблицей — поле фильтрации: мгновенно сужает список без запросов к серверу. Заголовки колонок кликабельны — сортировка по TTL, хитам или размеру.
У каждого ключа — кнопка удаления. Позволяет сбросить один конкретный ключ, не трогая всё остальное.
Логи
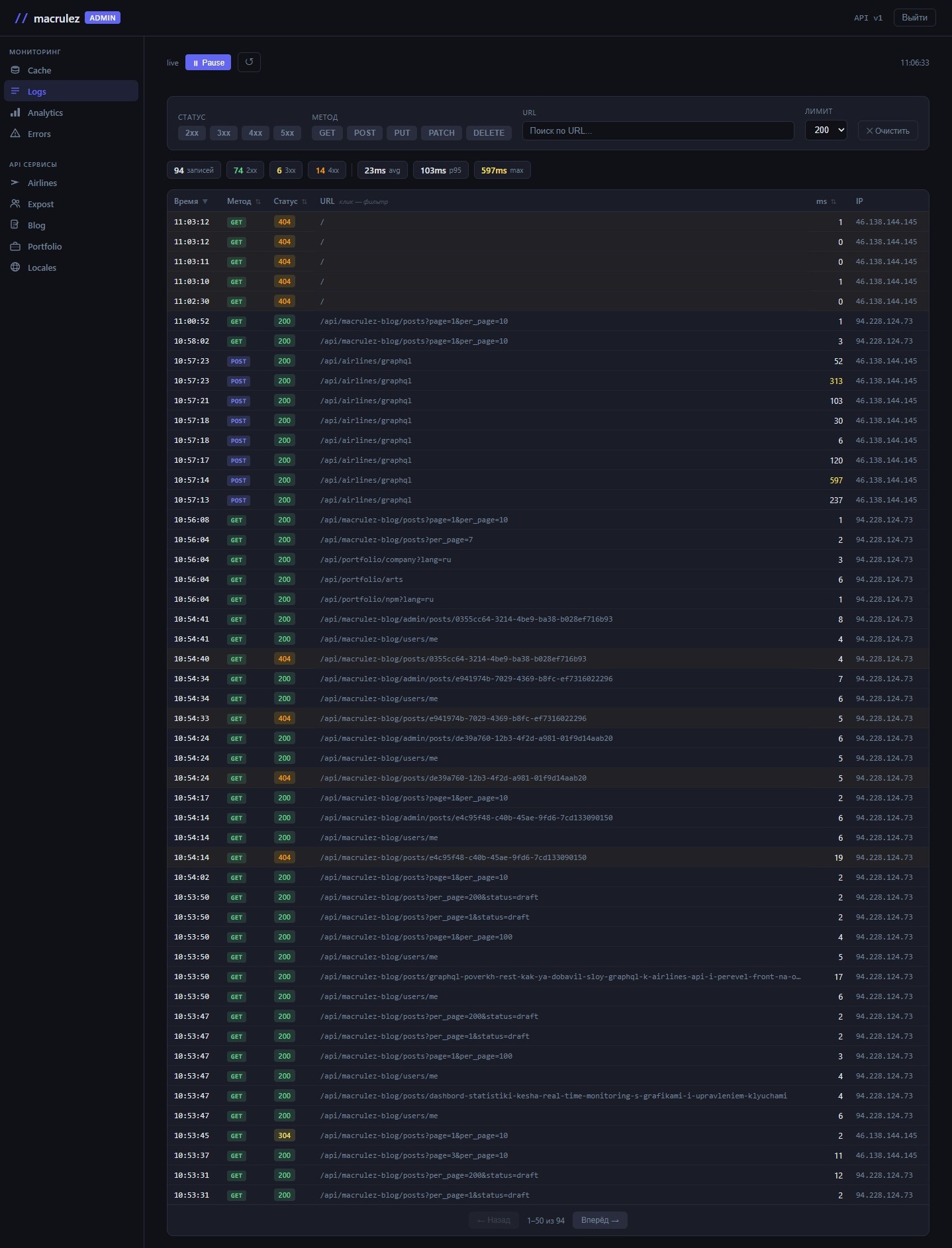
Раздел «Логи» — таблица всех HTTP-запросов к серверу. Бэкенд ведёт кольцевой буфер на 5000 последних записей с персистентностью в ndjson-файл: при перезапуске сервера история восстанавливается из файла.
Фильтры
Четыре фильтра над таблицей, работают совместно. Статус: диапазоны 2xx / 3xx / 4xx / 5xx. Метод: GET / POST / PUT / DELETE / PATCH. Поиск по URL: текстовое поле, частичное совпадение. Лимит: сколько последних записей загружать с сервера.
При изменении любого фильтра пагинация сбрасывается на первую страницу.
Таблица
Каждая строка: метка времени с точностью до секунды, метод с цветовым кодированием (GET — нейтральный, POST/PUT/PATCH — синеватый, DELETE — красноватый), URL с обрезкой длинных хвостов через ellipsis, HTTP-статус с цветом по диапазону (2xx — нейтральный, 4xx — жёлтый, 5xx — красный), длительность в миллисекундах.
Заголовки колонок «Время», «Метод», «URL», «Статус», «ms» кликабельны — сортировка по любому полю. По умолчанию — по времени убыванием: последние запросы наверху.
Пагинация
50 записей на страницу. Под таблицей: «← Назад», счётчик «1–50 из 247», «Вперёд →». Счётчик показывает диапазон записей, а не номер страницы — сразу видно, на каком месте в выборке находишься.
Аналитика
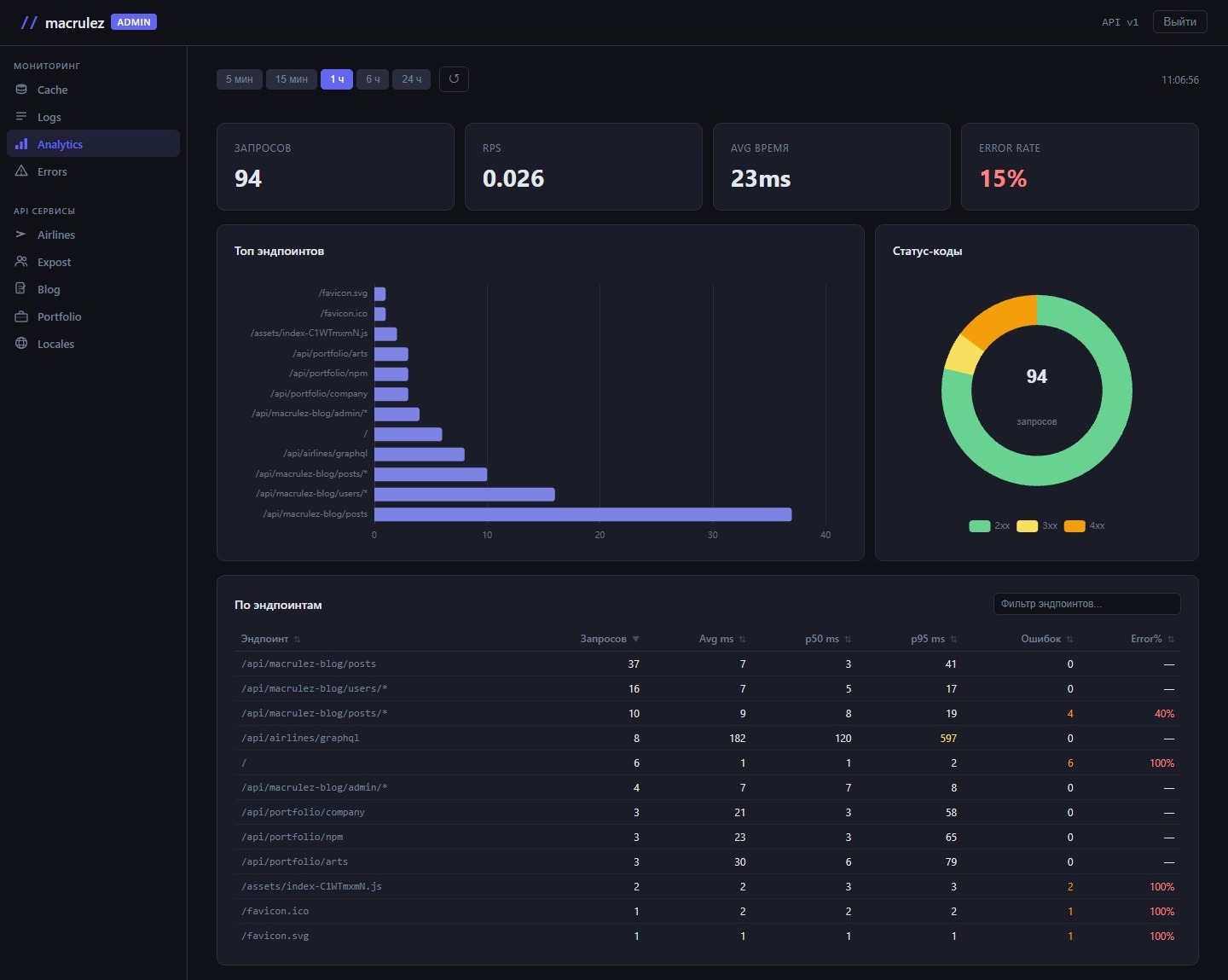
Раздел «Аналитика» — детальная статистика API за выбранный период: 1 час, 6 часов, 24 часа или неделя. Переключатель окна сверху — данные перезагружаются сразу.
Диаграммы
Сверху — два ряда графиков. В первом ряду два donut-чарта: распределение запросов по статусам (2xx / 3xx / 4xx / 5xx) и соотношение успешных к ошибочным. В центре каждого кольца — итоговое число.
Во втором ряду — линейный график latency по времени и bar-chart с топом медленных эндпоинтов. По линейному графику можно увидеть точный момент, когда latency начала расти, и сопоставить с деплоем или ростом нагрузки.
Таблица эндпоинтов
Основная часть раздела — таблица. Для каждого эндпоинта: количество запросов за период, ошибок, error rate, среднее время ответа, p50 и p95. URL нормализованы: динамические сегменты начиная с четвёртого уровня заменяются на *. Это значит, что /api/posts/slug-one и /api/posts/slug-two объединяются в одну строку /api/posts/* с суммарной статистикой. Без нормализации в таблице было бы несколько сотен строк вместо нескольких десятков.
Заголовки всех колонок кликабельны. Повторный клик меняет направление сортировки. Стрелка ▲ или ▼ показывает текущее состояние.
Над таблицей — поле фильтрации по URL. Написал /api/cache — в таблице остались только строки с этим фрагментом. Фильтр работает мгновенно, без запросов к серверу.
Ошибки
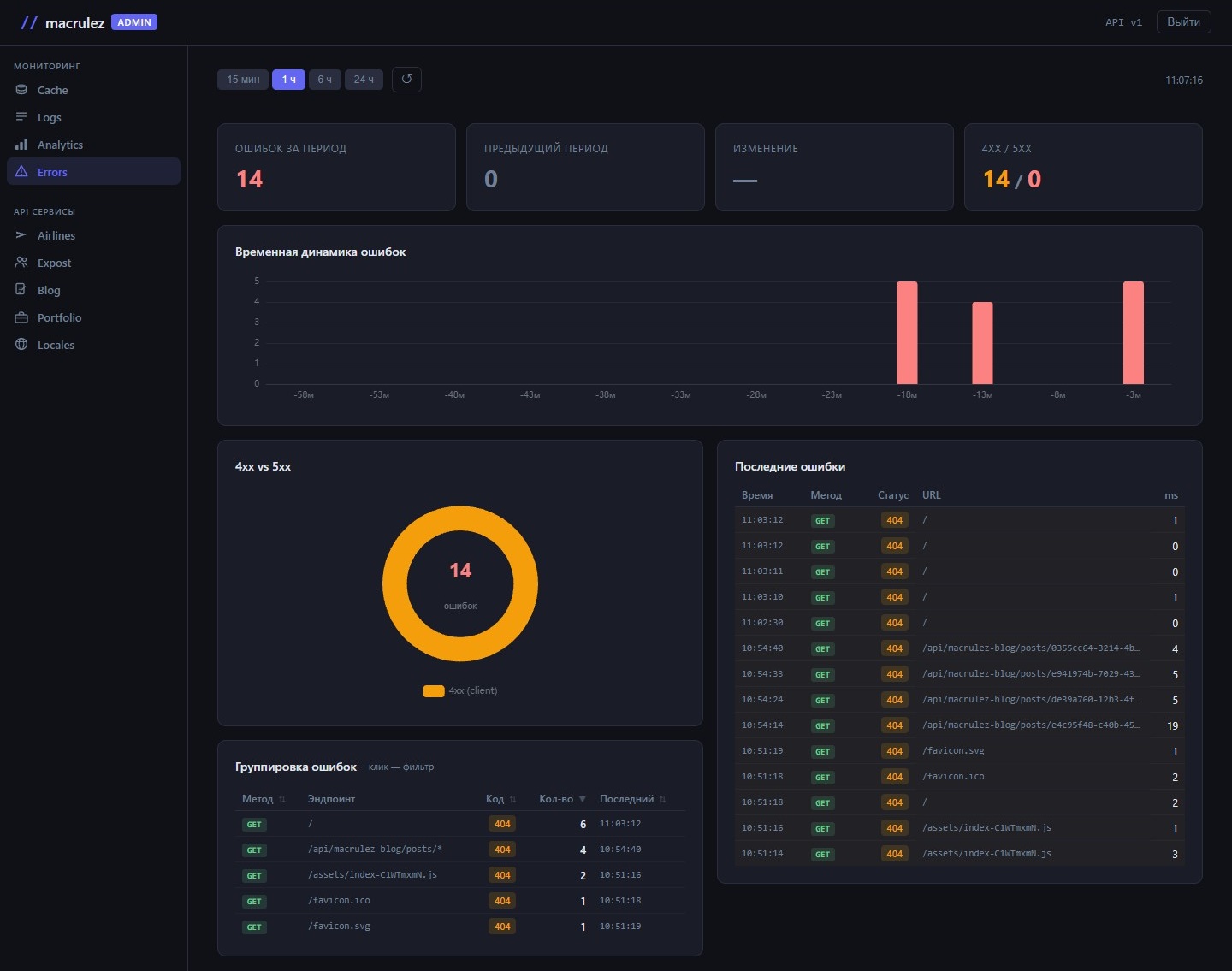
Раздел «Ошибки» — только запросы с 4xx и 5xx статусами, структурированные специально для понимания картины: растут ли ошибки, когда случился всплеск, какой эндпоинт виноват.
Карточки
Четыре числа наверху: ошибок в текущем окне, ошибок в предыдущем окне того же размера, дельта в процентах и распределение 4xx / 5xx.
Дельта — самая ценная из этих четырёх цифр. Не «было 42 ошибки», а «на 38% больше, чем в предыдущий такой же период». Красная стрелка вверх даже при небольшом абсолютном числе — сигнал, что что-то изменилось.
Распределение 4xx / 5xx важно само по себе: 4xx — обычно клиентские ошибки, 5xx — серверные. Всплеск 5xx при стабильных 4xx — явный признак проблемы на сервере.
Временная динамика
Барный график: 12 бакетов за выбранное окно. При окне 1 час каждый столбец — 5 минут, при 24 часах — 2 часа на столбец. Ось X подписана относительными метками: -5м, -10м, -1ч и т.д.
Данные считаются на бэкенде из полного массива ошибок за окно, а не из последних N записей. Это важно: при большом окне и высокой нагрузке ранние ошибки иначе выпадали бы из расчёта.
Группировка ошибок
Таблица с группировкой: метод + нормализованный URL + статус-код. Каждая уникальная комбинация — отдельная строка с количеством срабатываний и временем последней ошибки. Заголовки сортируемые.
Клик по строке фильтрует блок «Последние ошибки» ниже: показываются только записи из этой группы. Рядом с заголовком блока появляется чип с именем активного фильтра и крестиком для сброса.
Последние ошибки
Список последних 30 ошибочных запросов: время, метод, полный URL с query string, HTTP-статус, длительность. Если активен групповой фильтр — только записи из группы, иначе все подряд.
API-сервисы
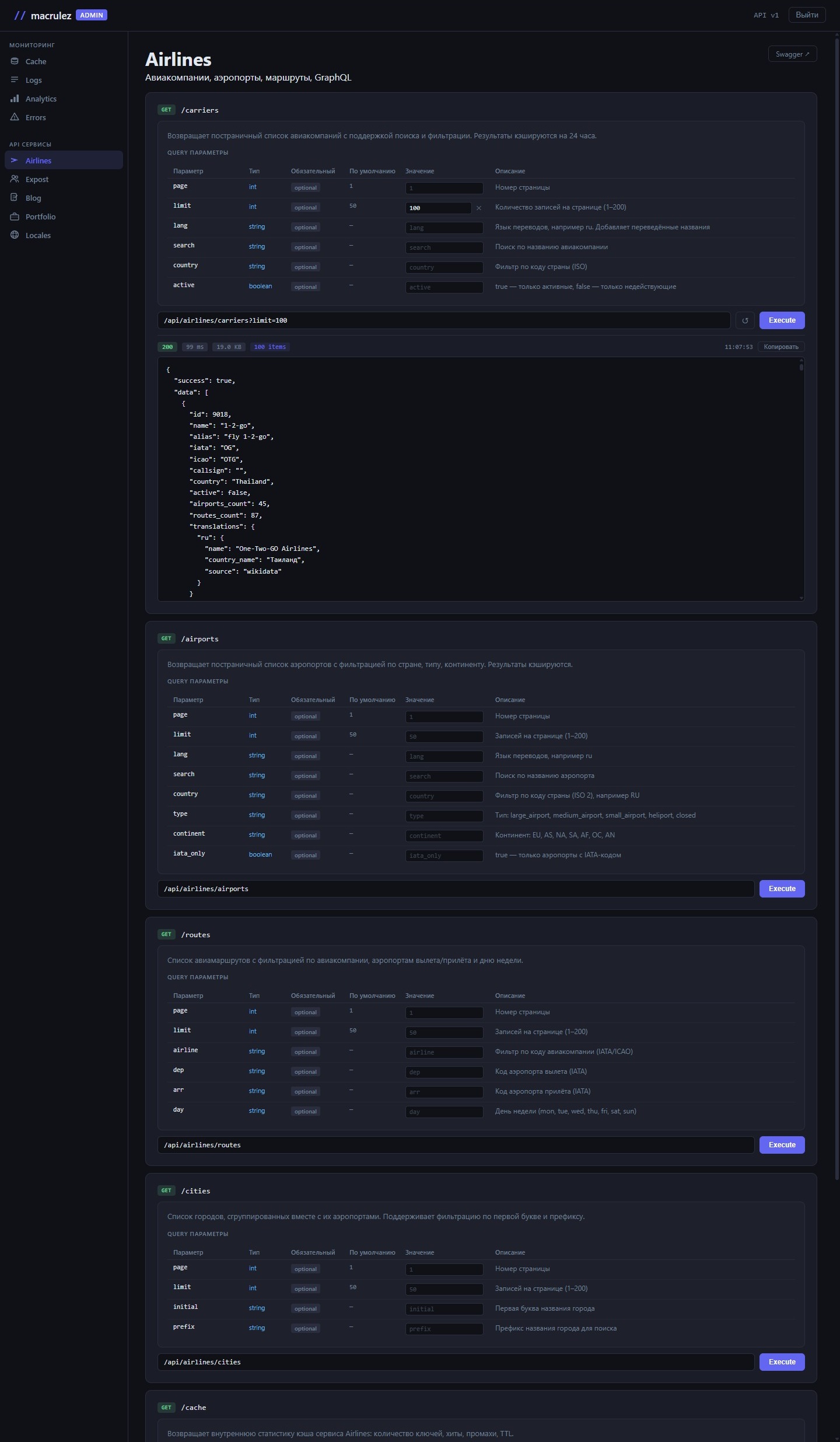
Последний раздел — интерактивный справочник по всем эндпоинтам сервиса. Не внешняя документация, не Swagger на отдельном порту — встроенная вкладка в той же admin-панели.
Навигация и документация
Слева — сайдбар с группами: «База данных», «Кэш», «Логи», «Система», «Аналитика». Клик по группе раскрывает список эндпоинтов с методом и путём. Клик по эндпоинту открывает детальный вид справа.
Вверху детального вида — метод и полный путь URL. Под ним — таблицы параметров: Path params, Query params, Body. Для каждого параметра: имя, тип данных, флаг обязательности, значение по умолчанию, описание.
Ширины колонок фиксированы одинаково для всех таблиц всех эндпоинтов: имя — 130 px, тип — 72 px, обязательность — 100 px, значение по умолчанию — 96 px, значение пользователя — 154 px, описание — весь остаток. Таблицы выглядят единообразно независимо от контента.
Поля значений и выполнение запроса
У Query params есть дополнительная колонка «Значение». В каждой строке — поле ввода. Вводишь значение — оно сразу дописывается в строку URL в шапке. Несколько полей работают одновременно: параметры накапливаются в query string. Рядом с каждым полем — кнопка ✕: нажал — значение очищается, параметр удаляется из URL. Остальные параметры не трогаются. URL можно также редактировать вручную — поле редактируемое.
Кнопка «Выполнить» отправляет запрос к API с Bearer-авторизацией. Под таблицами параметров появляется блок ответа: HTTP-статус с цветом, время выполнения в мс, заголовки ответа, тело ответа с подсветкой синтаксиса JSON и кнопкой «Скопировать». Если запрос вернул ошибку — статус красный, тело ошибки отображается так же.
Кнопка «Сбросить» рядом с «Выполнить» возвращает URL к исходному шаблону и очищает все введённые значения.
Пример: разбираем всплеск ошибок
Вот как это работает в связке. Открываю панель утром, дашборд показывает error rate 4.2% — жёлтый, не красный, но выше обычного. RPS в норме, аптайм не трогали, деплоев с вечера не было.
Иду в «Ошибки». Карточка с дельтой: ошибок в текущем часовом окне на 61% больше, чем в предыдущем. Всё в 5xx, 4xx не изменились. Тайм-лайн: всплеск начался около 7:40, дальше ровно держится.
В таблице групп — одна доминирующая строка: GET /api/airlines/* 503, 38 срабатываний за час. Кликаю по строке — «Последние ошибки» фильтруются. Время ответа у всех — от 800 мс до 2 секунд, потом 503.
Иду в «Аналитику», выставляю окно 6 часов, ввожу в фильтр /api/airlines. Сортирую по p95: у /api/airlines/graphql p95 — 1840 мс, у остальных эндпоинтов авиалиний — в пределах 200 мс. Проблема локализована.
Перехожу в «Логи», ставлю фильтр: метод GET, статус 5xx, URL /api/airlines. Все ошибки с одинаковым телом — таймаут базы данных. Возвращаюсь на дашборд: пул соединений — 10 всего, 0 idle. Пул исчерпан.
Иду в «API-сервисы», нахожу эндпоинт статистики БД, выполняю запрос прямо из браузера — вижу активные соединения и один запрос, который висит уже 12 минут. Дальше — уже дело к коду, не к панели.
Весь путь от «что-то не так» до «вот конкретный запрос, который всё блокирует» занял меньше пяти минут. Раньше это был docker logs | grep плюс ручные запросы через curl.