Тайлы, открытые данные и маршрутные сети авиакомпаний
Давно хотел сделать что-то визуально интересное и технически нетривиальное — не очередной todo-лист и не клон какого-нибудь туториала, а что-то своё, с реальными данными и понятным смыслом. В итоге получился проект airlines.macrulez.ru — интерактивная карта маршрутных сетей авиакомпаний. Выбираешь авиакомпанию из списка, и видишь откуда и куда она летает: дуги маршрутов, точки аэропортов, подписи городов. Всё рисуется на canvas поверх тайловой карты мира.
В посте расскажу, как это устроено изнутри — от генерации тайлов и сбора данных до REST API и рендеринга на фронтенде. Получилось довольно много всего, поэтому разобью по частям.
Часть 1. Тайлы карты мира
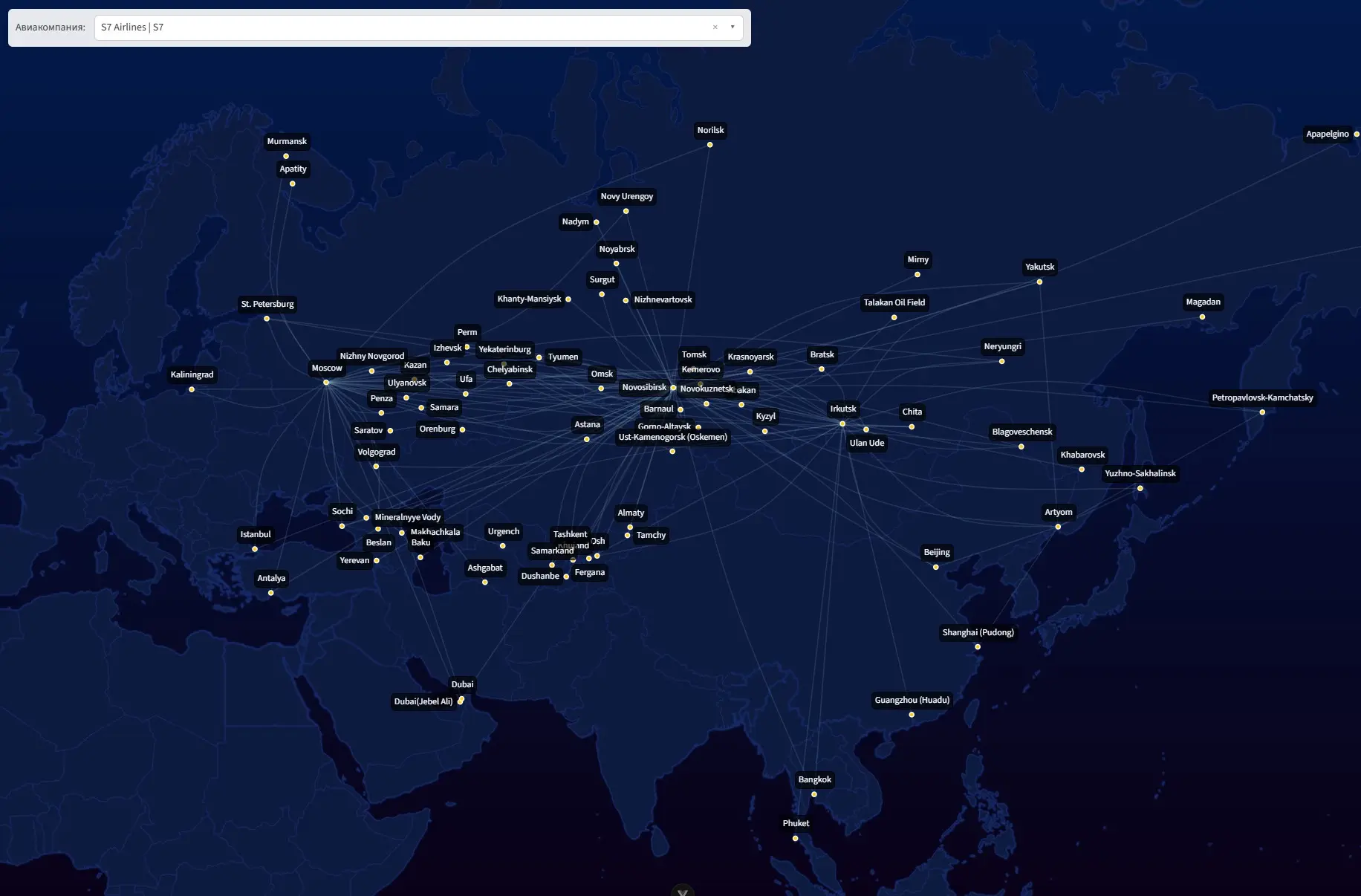
Первое, что нужно для любого картографического проекта — сама карта. Казалось бы, очевидное решение — взять OpenStreetMap или любой другой публичный tile-сервер. Но это зависимость от внешнего сервиса: сегодня работает, завтра поменяли политику или просто лежат. Плюс OSM содержит избыточную детализацию: улицы, здания, маршруты общественного транспорта. Для карты маршрутных сетей авиакомпаний всё это не нужно — достаточно контуров стран и береговых линий.
Поэтому решил сгенерировать тайлы самостоятельно.
Источник данных — GeoJSON
Взял публичные данные о границах стран и континентов в формате GeoJSON. Это стандартный открытый формат: каждая страна описана набором полигонов с координатами в виде пар [longitude, latitude]. Данные бесплатные, несколько мегабайт — граница каждой страны с достаточной точностью для мирового масштаба.
Как работает тайловая сетка
Система тайлов устроена просто. Весь мир делится на квадратные тайлы по схеме z/x/y:
z— уровень зума (масштаб)x— горизонтальная координата тайла в сеткеy— вертикальная координата
На каждом следующем уровне зума количество тайлов умножается на четыре: zoom 0 — один тайл на весь мир, zoom 1 — четыре, zoom 2 — шестнадцать, zoom 3 — шестьдесят четыре, и так далее. Формула: 4^z тайлов на уровне z.
Скрипт генерации работает так: для каждого тайла вычисляем географические границы (bbox), берём из GeoJSON только те полигоны, которые попадают в этот bbox, проецируем координаты в пиксельное пространство и рисуем на PNG-холсте нужного размера. Получаем набор файлов 0/0/0.png, 1/0/0.png, 1/0/1.png и так далее.
Для маршрутных сетей хватило нескольких уровней зума — детализация на уровне улиц нам просто не нужна. Важно видеть форму континентов, границы стран и береговую линию, остальное лишнее.
Хранение тайлов
Готовые тайлы загрузил в S3-совместимое объектное хранилище. Фронтенд забирает их по URL вида /{z}/{x}/{y}.png — это стандартный tile-протокол, который понимают все картографические движки. Никакого tile-сервера, никакого посредника — просто статика из S3.
Часть 2. Данные об авиакомпаниях и маршрутах
С картой разобрались. Теперь нужны данные: авиакомпании, аэропорты, маршруты. Причём данные живые — не CSV-файл за 2019 год, а актуальные, с возможностью обновления.
AirLabs API
Первый источник — AirLabs (airlabs.co). Это коммерческое API с авиационными данными. Есть бесплатный tier на 1000 запросов в месяц — для периодических обновлений хватает.
Оттуда брал:
- Список авиакомпаний с IATA и ICAO-кодами, названиями, странами регистрации и флагами активности.
- Маршруты тоже можно загружать через AirLabs, но лимит в 1000 запросов быстро кончается, если авиакомпаний много. Ryanair один летит в 237 аэропортов — это уже несколько запросов только на одну АК.
Поэтому для маршрутов нашёл другое решение.
GitHub: Jonty/airline-route-data
Репозиторий Jonty/airline-route-data на GitHub — бесплатный открытый источник маршрутных данных, который обновляется еженедельно. Данные в JSON, структура простая: для каждой авиакомпании список маршрутов в виде пар аэропортов.
Написал скрипт, который клонирует (или обновляет) этот репозиторий и парсит маршруты. Каждая пара dep_iata → arr_iata пишется в базу батчами по 500 записей — так и быстрее, и не нагружает базу тысячами одиночных INSERT.
Перед загрузкой новых маршрутов старые для той же авиакомпании удаляются — чтобы не копились мёртвые маршруты от старых расписаний.
Переводы через Wikidata SPARQL
Отдельная задача — названия на русском языке. AirLabs отдаёт только английские названия. Брать переводы из платных источников не хотелось.
Решение — Wikidata SPARQL. Wikidata — публичная база знаний от фонда Wikimedia, где хранятся структурированные данные в том числе для авиакомпаний и аэропортов. SPARQL — язык запросов к этой базе. Доступ бесплатный, без API-ключа.
Написал хелперы fetchAirlineTranslationsBatched и fetchAirportTranslationsBatched. Они формируют SPARQL-запрос, передают батч из 50 объектов (больше сервер начинает отклонять), получают переводы и сохраняют в отдельные таблицы. Потом при запросе к API переводы джойнятся к основным данным.
Часть 3. База данных и скрипты импорта
В качестве БД — PostgreSQL, запущенный в Docker-контейнере. Схема получилась довольно плоская — никаких хитрых связей, всё через IATA-коды:
airlines— авиакомпании: IATA, ICAO, название на английском, страна, флагactiveworld_airport— аэропорты: IATA, ICAO, координаты (latitude_deg,longitude_deg), тип (large_airport,medium_airportи т.д.), страна, городroutes— маршруты:dep_iata,arr_iata,airline_iata,last_updatedairline_translations— переводы авиакомпаний:iata,lang,nameairport_translations— переводы аэропортов:iata_code,lang,name,city
Всё взаимодействие с базой идёт через databaseService — это собственная обёртка с методами select() и execute(). Поддерживает параметризованные запросы (чтобы не было SQL-инъекций), и встроенное кеширование с TTL — передаёшь запрос, параметры и время жизни кеша, дальше сервис сам решает, идти в базу или отдать закешированный результат.
Для статистических запросов, которые дёргаются при каждой загрузке страницы, TTL = 3600 секунд (1 час). Данные об авиакомпаниях и маршрутах меняются редко — смысла каждый раз бить в базу нет. Для редактирующих операций кеш сбрасывается вызовом clearCache().
Последовательность импорта
Скрипты импорта написаны на Node.js. Запускаются вручную или по расписанию. Порядок такой:
- Авиакомпании из AirLabs — загружаем список, пишем в
airlines. Если запись с таким IATA уже есть — обновляем, иначе вставляем. - Аэропорты — аналогично, с координатами и типами. Координаты критически важны: без них маршрут не нарисовать.
- Маршруты из GitHub — клонируем/обновляем репозиторий, парсим JSON, батч-инсерт по 500 записей. Старые маршруты АК предварительно чистим.
- Переводы из Wikidata — запускаем отдельно. Скрипт находит записи без перевода на нужный язык и батчами (по 50 штук) тянет из Wikidata.
Между запросами к AirLabs — пауза 200ms. Это стандартная защита от rate limit: лучше потерять несколько минут на паузах, чем получить 429 на середине импорта и потом разбираться что успело записаться, а что нет.
Часть 4. REST API
Backend — Node.js + Express, тоже в Docker. Три основных контроллера, каждый отвечает за свою предметную область.
routeController — маршруты
Самый нагруженный контроллер. Ключевые эндпоинты:
GET /api/airlines/routes/stats/airlines — возвращает список авиакомпаний, у которых в базе есть хотя бы один маршрут, с агрегированной статистикой: количество маршрутов, число аэропортов вылета и прилёта, количество уникальных пар. Сортировка по убыванию числа маршрутов. Ответ кешируется на час — эти данные меняются только при обновлении базы. На фронтенде именно этот эндпоинт используется для заполнения селектора авиакомпаний: показываем только тех, у кого реально есть данные.
GET /api/airlines/routes/airline/:iata/destinations — полная маршрутная сеть конкретной АК. Возвращает все пары dep_iata → arr_iata с базовой информацией об аэропортах. Это тяжёлый запрос — у крупных АК 5000+ маршрутов. Поэтому тоже кешируется.
GET /api/airlines/routes/airline/:iata/from/:airport и /to/:airport — маршруты из конкретного аэропорта и в него. Удобно для drill-down по географии.
Внутри запросы строятся динамически через WHERE-условия, джойнятся с таблицами world_airport и airlines. Для агрегации в PostgreSQL используется array_agg() — это позволяет в одном запросе собрать, например, все номера рейсов в массив, не делая N отдельных запросов.
airlineController — авиакомпании
Поиск работает сразу по нескольким полям: имя, IATA, ICAO, позывной. Плюс поиск в таблице переводов через EXISTS-подзапрос — чтобы если ввести «Аэрофлот», нашёлся SU.
Через параметр lang=ru к каждой авиакомпании в ответе прикрепляется перевод из airline_translations. Реализовано через хелпер attachTranslations, который батчами джойнит переводы к уже загруженным записям.
Статус active обновляется отдельным эндпоинтом: сравниваем текущие записи с тем, что отдаёт AirLabs, и проставляем флаги.
airportController — аэропорты
По сути справочник. Поиск по имени, IATA, ICAO, городу. Фильтрация по стране (iso_country) и типу аэропорта. Отдельный эндпоинт GET /api/airlines/airports/iata/:code — точечный lookup по IATA-коду. Он используется на фронтенде, когда встречается аэропорт, которого нет в локальном кеше.
Формат ответов везде единообразный:
json
{
"success": true,
"data": [...],
"pagination": { "total": 885, "limit": 200, "offset": 0 }
}Часть 5. Фронтенд и рендеринг маршрутов
Фронтенд — Vue 3 + TypeScript, сборка на Vite. Никаких картографических библиотек типа Leaflet или Mapbox — всё на голом canvas. Это принципиальное решение: хотелось полного контроля над тем, как рисуются маршруты, без борьбы с чужими абстракциями.
Инициализация
При загрузке страницы запускается PipelineOrchestrator из библиотеки rest-pipeline-js — он выполняет несколько запросов последовательно:
/api/airlines/routes/stats/airlines— список АК для селектора (только те, у кого есть маршруты)/api/airlines/airports?country=RU&type=large_airport&limit=200— крупные аэропорты РФ/api/airlines/airports?country=RU&type=medium_airport&limit=200— средние аэропорты РФ
Аэропорты сразу раскладываются в локальный airportCache — словарь { [iata]: { iata, name, lat, lon } }. Этот кеш живёт на всё время сессии и пополняется на лету.
Выбор авиакомпании и загрузка маршрутов
Когда пользователь выбирает АК из списка, срабатывает watch(selectedAirline) и запускается загрузка маршрутной сети:
GET /api/airlines/routes/airline/{iata}/destinationsОтвет содержит массив пар { dep_iata, arr_iata }. Для каждого IATA-кода проверяем кеш: если аэропорт уже есть — берём оттуда координаты. Если нет — догружаем точечно через /api/airlines/airports/iata/{iata}. Таких «незнакомых» аэропортов обычно немного — в основном это экзотические направления за пределами России.
После загрузки маршруты перегруппировываются в формат [{ departure: 'SVO', arrival: ['LED', 'AER', ...] }, ...] и передаются в composable useDrawAirlines, который занимается отрисовкой.
Рендеринг на canvas
Карта состоит из двух слоёв:
Canvas — тут рисуется всё: тайлы карты, дуги маршрутов, кружки аэропортов. Зум и панорамирование тоже обрабатываются здесь через pointer events.
HTML-оверлей — поверх canvas, с pointer-events: none, находится слой с подписями аэропортов в виде обычных <div>. Это даёт несколько преимуществ по сравнению с отрисовкой текста на canvas: нормальное сглаживание шрифтов, возможность кликнуть по метке, стандартные CSS-анимации. Клики на метках обрабатываются с маленькой хитростью — если пользователь не просто кликнул, а начал тащить карту, событие перехватывается и форвардится на canvas, чтобы не прерывать панорамирование.
Маршруты рисуются как кривые Безье — прямые линии между аэропортами выглядели бы слишком грубо на сферической проекции, а дуги смотрятся естественно и визуально ближе к реальным траекториям полётов.
Кеширование визуализации
Наивный подход — перерисовывать всё на каждый кадр — быстро упирается в производительность. У Ryanair 5000+ маршрутов, каждый — кривая Безье с вычислением контрольных точек, разнесением по lane'ам и двухпроходной отрисовкой (сначала обычные, потом подсвеченные поверх). Перерисовывать это при каждом движении мыши — гарантированные фризы.
Решение — трёхуровневое offscreen-кеширование. Для маршрутов, точек аэропортов и подписей городов создаются отдельные offscreen-канвасы, которые перерисовываются только когда это действительно нужно, а в остальное время просто композитятся на основной canvas со смещением.
Маршруты (linesCanvas) — самый тяжёлый слой. Все дуги рисуются на отдельный offscreen-канвас, размер которого — viewport плюс большой margin с каждой стороны (равен max(width, height)). При панорамировании кешированная картинка просто сдвигается — никакой перерисовки. Перерендер запускается только когда пользователь утаскивает карту достаточно далеко (>75% margin'а), меняет выделенный город или выбирает другую авиакомпанию.
Точки аэропортов (citiesCanvas) — аналогичная схема: offscreen-канвас с margin'ом, композитинг при пане, перерисовка при дрифте или смене выделения.
Подписи городов (cachedLabelPlacements) — здесь кеш другого рода. Подписи рисуются не на canvas, а рендерятся как HTML-элементы через Vue. Но для каждой подписи нужно определить placement — с какой стороны от точки её разместить, чтобы она не перекрывала ни другие подписи, ни соседние точки. Это O(n²) проход с проверкой пересечений прямоугольников. Вычисление запускается при смене АК, смене выделенного города или при зуме, а при панорамировании направления placement'ов берутся из кеша и только пересчитываются координаты — простое сложение смещений, без overlap detection.
Зум обрабатывается отдельно. Пока пользователь крутит колесо, перерисовывать offscreen-канвасы на каждое событие слишком дорого. Вместо этого кешированная картинка масштабируется через drawImage с пересчитанными размерами — получается слегка пикселизованный превью, зато 60 fps. Полноценная перерисовка запускается с debounce 250ms после последнего события зума.
Дополнительно все draw-вызовы при быстром перемещении throttled через requestAnimationFrame — если за один кадр приходит несколько pointermove, рисуется только один раз.
Итого
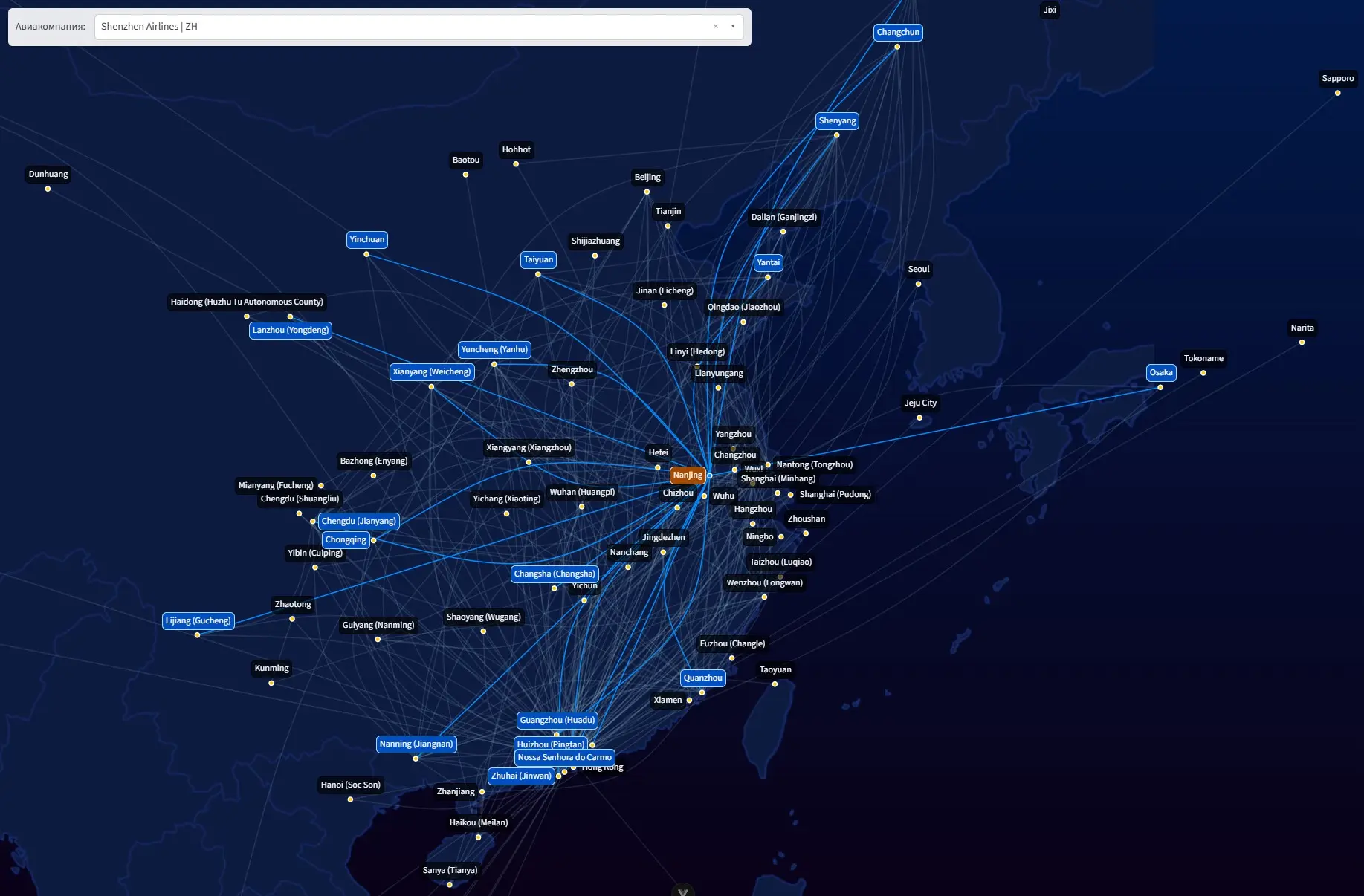
В проекте сошлись несколько отдельных задач, которые я хотел порешать:
- Работа с геоданными и генерация тайлов — раньше не делал
- Сбор и нормализация данных из разных источников (API с лимитами, открытые репозитории, SPARQL)
- Проектирование REST API с кешированием на уровне сервиса
- Рендеринг на canvas без картографических библиотек
По ощущениям, самое интересное — это работа с данными. Авиационные данные — это тот случай, когда формально всё открыто, но собрать актуальную и полную картину из одного источника не получится: где-то лимит запросов, где-то устаревшие данные, где-то нет переводов. Пришлось комбинировать несколько источников и писать скрипты нормализации.
Всё крутится на собственном сервере в Docker. Данные периодически обновляются скриптами. Посмотреть можно на airlines.macrulez.ru.